Feature-Based vs. GAN-Based Imitation: When and Why
 Learning from demonstrations: Feature-based vs. GAN-based methods
Learning from demonstrations: Feature-based vs. GAN-based methodsDisclaimer
The terminology surrounding the use of offline reference data in reinforcement learning (RL) varies widely across the literature. Terms such as imitation learning, learning from demonstrations, and demonstration learning are often used interchangeably, despite referring to subtly different methodologies or assumptions.
In this survey, we adopt the term learning from demonstrations to specifically denote a class of methods that utilize state-based, offline reference data to derive a reward signal. This reward signal quantifies the similarity between the behavior of a learning agent and that of the reference trajectories, and it is used to guide policy optimization.
Motivation and Scope
While learning from demonstrations has become a widely adopted strategy in both robotics and character animation, the field lacks consistent guidance on when to prefer particular classes of methods, such as feature-based versus GAN-based approaches. Practitioners often adopt one method over another based on precedent or anecdotal success, without a systematic analysis of the algorithmic factors that underlie their performance. As a result, conclusions drawn from empirical success may conflate algorithmic merit with incidental choices in reward design, data selection, or architecture.
The objective of this article is to provide a principled comparison between feature-based and GAN-based imitation methods, focusing on their fundamental assumptions, inductive biases, and operational regimes. The exposition proceeds in two stages. First, we review the problem setting from the perspective of physics-based control and reinforcement learning, including the formulation of reward functions based on reference trajectories. Second, we examine the historical development and current landscape of imitation methods, organized around the type of reward structure they use, explicit, feature-based formulations versus implicit, adversarially learned metrics.
Our goal is not to advocate for one approach over the other in general, but to clarify the conditions under which each is more suitable. By articulating the trade-offs involved—including scalability, stability, generalization, and representation learning, we aim to provide a conceptual framework that supports more informed method selection in future work.
Physics-Based Control, States and Actions
In both character animation and robotics, physics-based control refers to a paradigm in which an agent’s behavior is governed by the underlying physical dynamics of the system, either simulated or real. Rather than prescribing trajectories explicitly, such as joint angles or end-effector poses, this approach formulates control as a process of goal-directed optimization, where a policy generates control signals (e.g., torques or muscle activations) to maximize an objective function under physical constraints. This stands in contrast to kinematics-based or keyframe-based methods, which often disregard dynamics and focus on geometrically feasible but potentially physically implausible motions. Physics-based control ensures that resulting behaviors are not only kinematically valid but also dynamically consistent, energy-conservative, and responsive to interaction forces, making it particularly suited for tasks involving locomotion, balance, and physical interaction in uncertain or dynamic environments.
In this context, the state $s \in \mathcal{S}$ typically encodes the agent’s physical configuration and dynamics, such as joint positions, joint velocities, root orientation, and may include exteroceptive inputs like terrain geometry or object pose. The action $a \in \mathcal{A}$ corresponds to the control input applied to the system, most commonly joint torques in torque-controlled settings, or target positions in PD-controlled systems. In biomechanical models, actions may also represent muscle activations. By integrating these elements within a physics simulator or physical system, physics-based control enables emergent behaviors that are compatible with real-world dynamics, allowing policies to discover strategies that are not only effective but also physically feasible.
Rethinking Learning from Demonstrations
In the context of learning from demonstrations, reward functions are typically derived from reference data, rather than being manually engineered to reflect task success or motion quality. This setup leverages recorded trajectories, often collected from motion capture, teleoperation, or other expert sources, to define a notion of behavioral similarity. The policy is then optimized to minimize this discrepancy, encouraging it to reproduce motions that are consistent with those in the demonstration dataset.
Critically, the reward derived from demonstrations may serve either as a pure imitation objective, where the policy is expected to replicate the demonstrated behavior as closely as possible, or as a regularizing component that biases learning while allowing task-specific objectives to dominate. This dual role makes demonstration-based rewards particularly valuable in high-dimensional control problems where exploration is difficult and task-based rewards are sparse or poorly shaped. As such, learning from demonstrations transforms the design of the reward function from a manual engineering problem into one of defining or learning an appropriate similarity metric between agent and expert behavior, either explicitly, through features, or implicitly, through discriminators or encoders.
This role becomes especially important as the complexity of the environment and agent increases. In lower-dimensional settings, carefully engineered reward functions or manually designed curricula have proven sufficient to elicit sophisticated behaviors through reinforcement learning alone. However, such strategies do not scale effectively to systems with high-dimensional state-action spaces, where naïve exploration is inefficient and reward shaping becomes brittle or intractable. Under these conditions, demonstration data offers a practical alternative to reward or environment shaping, acting as an inductive bias that accelerates the discovery of viable behaviors. In this light, reference motions are not ancillary constraints but primary learning signals, particularly in regimes where task-based supervision is sparse or difficult to specify. This reframing justifies the use of demonstrations not only for imitation but as a foundation for scalable and data-efficient policy learning.
Feature-Based Imitation: Origins and Limitations
Feature-based imitation approaches can be traced back to DeepMimic, which established a now-standard formulation for constructing reward signals based on explicit motion matching. In this framework, the policy is aligned with a reference trajectory by introducing a phase variable, which serves as a learned proxy for temporal progress through the motion. The reward is computed by evaluating feature-wise distances—such as joint positions, velocities, orientations, and end-effector positions—between the policy-generated trajectory and the reference, synchronized via the phase.
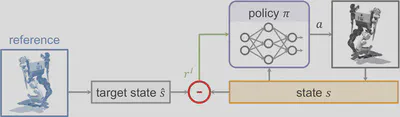
Owing to their dense and explicit reward structure, these methods are highly effective at reproducing fine-grained motion details. However, their scalability to diverse motion datasets is limited. While DeepMimic introduces a one-hot motion identifier to enable multi-clip training, this encoding does not model semantic or structural relationships between different motions. As a result, the policy treats each motion clip as an isolated objective, which precludes generalization and often leads to discontinuities at transition points.
What is missing in this setup is a structured representation space over motions—one that captures both temporal progression and the underlying topology of behavioral variation. Such representations enable not only smoother transitions between behaviors but also facilitate interpolation, compositionality, and improved generalization to motions not seen during training. Policies trained over these structured motion spaces are better equipped to synthesize new behaviors while preserving physical plausibility and stylistic fidelity.
Implicit Rewards for Motion Diversity: GAN-Based Imitation
To address the limitations of feature-based approaches in handling diverse motion data, Adversarial Motion Priors (AMP) introduced the use of adversarial training, building on earlier frameworks such as GAIL, where expert action labels are assumed.
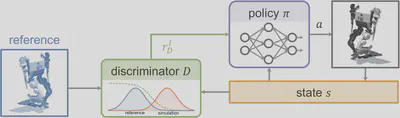
From an optimization standpoint, GAN-based methods treat the policy as a generator in a two-player minimax game. These methods scale naturally to large and diverse motion datasets, as they operate on short, fixed-length transition windows, typically spanning two to eight frames, rather than full trajectories. This removes the need for phase-based or time-indexed alignment, making them particularly effective in unstructured datasets. Additionally, the discriminator implicitly defines a similarity metric over motion fragments, allowing transitions that are behaviorally similar to receive comparable rewards even when not temporally aligned. As a result, policies trained under adversarial objectives tend to exhibit smoother transitions across behaviors compared to methods relying on discrete motion identifiers and hard switching. Because the reward is defined over distributional similarity, rather than matching a specific trajectory, AMP and related techniques are well-suited for stylization tasks or for serving as general motion priors that can be composed with task-specific objectives.
Despite their empirical success across domains, including character animation (e.g., InterPhys, PACER) and robotics, adversarial imitation introduces fundamental challenges that impact training reliability and policy expressiveness.
Discriminator Saturation
A key challenge in adversarial setups is that the discriminator can rapidly become overconfident, especially early in training when the policy generates trajectories that diverge significantly from the reference distribution. In this regime, the discriminator easily classifies all transitions correctly, producing near-zero gradients and leaving the policy without informative reward signals. This phenomenon is particularly problematic in high-dimensional or difficult environments, such as rough terrain locomotion or manipulation tasks, where meaningful exploration is essential but sparse.
Solutions such as Wasserstein-based objectives (e.g., WASABI, HumanMimic) aim to retain useful gradients and therefore reward signals even in the face of a strong discriminator.
Mode Collapse
Another failure mode is the collapse of behavioral diversity: the policy may converge to producing only a narrow subset of trajectories that reliably fool the discriminator, ignoring the wider variation present in the demonstrations. While the discriminator implicitly encourages local smoothness in the reward landscape, AMP lacks a structured motion representation that would enable global diversity or controllable behavior synthesis. Consequently, the resulting policies often underutilize the full range of skills present in the data.
To counteract this limitation, a variety of techniques introduce latent representations to provide structured control over motion variation. Unsupervised approaches like CASSI, ASE, and CALM learn continuous embeddings over motion space, optimizing mutual information between latent codes and observed behaviors to preserve diversity. These embeddings are then used to condition the policy, enabling the generation of distinct behaviors from different regions of the latent space. Other approaches rely on category-level supervision to guide the learning process. For example, Multi-AMP, CASE, and SMPLOlympics use motion class annotations to condition both the discriminator and the policy, thereby restricting collapse to occur only within class-specific subregions. In contrast, FB-CPR adopts a representation-based solution, learning forward-backward encodings to structure the discriminator’s feedback. Several other extensions train individual motion primitives progressively (e.g., PHC, PHC+). A conditioned skill composer is utilized to recover the motion diversity. Others introduce representation distillation with variational bottlenecks, as in PULSE, to form compressed yet expressive motion embeddings for controllable generation.
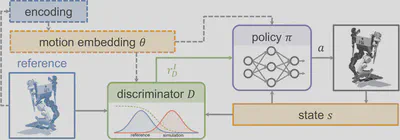
Together, these developments highlight both the flexibility and complexity of adversarial imitation learning. While GAN-based methods naturally scale to large and diverse datasets, they benefit substantially from the addition of structured motion representations, whether learned, annotated, or composed, to stabilize training and recover controllable, diverse behavior.
Feature-Based Imitation with Structured Representations
While adversarial imitation methods offer flexibility and scalability with diverse reference data, they impose significant practical burdens. Ensuring training stability, managing discriminator saturation, and preventing mode collapse often require extensive architectural tuning. These limitations have motivated a return to feature-based methods, now enhanced with structured motion representations, as a more interpretable and controllable alternative to adversarial training. The core insight behind this renewed direction is the importance of a well-structured motion representation space for enabling smooth transitions and generalization across behaviors.
This explicitness simplifies conditioning and reward design, often reducing the reward to weighted feature differences relative to a reference state.
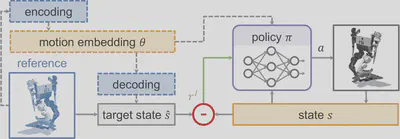
As a result, a new class of imitation approaches has emerged that maintains the explicit reward structure of traditional feature-based methods, but augments it with representation learning to scale across tasks and motions. In many cases, reference frames, or compact summaries thereof, are injected directly into the policy, providing frame-level tracking targets that guide behavior.
Sophisticated Motion Representation
A central challenge for this class of methods is the construction of motion representations that support smooth transitions and structural generalization. Compact, low-dimensional embeddings promote semantic understanding of inter-motion relationships and improve sample efficiency.
To this end, some methods inject reference features or full motion states directly into the policy (e.g., PhysHOI, ExBody, H2O, HumanPlus, MaskedMimic, ExBody2, OmniH2O, AMO, TWIST, GMT), preserving spatial coherence in the motion space. Others pursue more abstract embeddings through self-supervised or policy-conditioned learning. For instance, ControlVAE, PhysicsVAE, and NCP build representations via policy interaction, while VMP and RobotMDM construct temporally and spatially coherent embeddings using self-supervision. Frequency-domain methods such as PAE, FLD, and DFM impose motion-inductive biases that capture the periodic and hierarchical structure of motion. These techniques collectively extend the DeepMimic paradigm by generalizing phase alignment and structural similarity beyond heuristics.
Inflexible Imitation Adaptation
A limitation of these representation-driven feature-based methods is that they often rely on explicit tracking of full trajectories, enforced by dense per-step rewards. This design makes it difficult to adapt or deviate from the reference when auxiliary tasks require flexibility, as is common in goal-directed or interaction-heavy settings.
To address this, some approaches introduce mechanisms to adaptively relax imitation constraints. For example, MCP introduces a fallback mechanism that adjusts phase progression when key task objectives are not met. RobotKeyframing proposes a transformer-based attention model that encodes arbitrary sets of keyframes with flexible temporal spacing. ConsMimic proceeds with imitation of features only when the optimality constraints of the task are satisfied. Other works incorporate high-level planning components to dictate intermediate reference states, such as diffusion-based models in PARC and HMI, or planners that directly modulate the learned motion representations (e.g., VQ-PMC, Motion Priors Reimagined).
Together, these developments illustrate the interpretability and stability of feature-based imitation when paired with structured motion representations. However, despite avoiding the instability of adversarial training, these methods remain constrained by their reliance on explicit tracking and overengineered representations, which can hinder adaptation in tasks requiring flexible deviation from demonstrations.
Summary: Strengths, Limitations, and Emerging Directions
Learning from demonstrations has evolved into two primary methodological paradigms: feature-based methods, which use explicit, hand-crafted reward formulations, and GAN-based methods, which employ discriminators to implicitly shape behavior. Each offers distinct advantages and faces unique challenges, especially as the field shifts toward learning from large, diverse, and unstructured motion datasets.
| GAN-Based Methods | Feature-Based Methods |
|---|---|
| AMP, InterPhys | DeepMimic, PhysHOI, ExBody |
| PACER, WASABI, HumanMimic | H2O, HumanPlus, MaskedMimic |
| CASSI, ASE, CALM | ExBody2, OmniH2O, AMO |
| Multi-AMP, CASE | TWIST, GMT, ControlVAE |
| SMPLOlympics, FB-CPR, PHC | PhysicsVAE, NCP, VMP |
| PHC+, PULSE | RobotMDM, PAE, FLD |
| DFM, MCP, ConsMimic | |
| RobotKeyframing, PARC, HMI | |
| VQ-PMC, Motion Priors Reimagined |
GAN-Based Methods
GAN-based approaches, such as AMP and its derivatives, use a discriminator to assign reward signals based on the realism of short transition snippets. This formulation dispenses with time-aligned supervision, allowing policies to imitate motion in a distributional sense rather than reproducing specific trajectories. As a result, these methods scale naturally to unstructured or unlabeled data, enabling smoother transitions between behaviors and generalization beyond the demonstrated clips.
Recent advances mitigate some of the core challenges of GAN-based imitation, namely, discriminator saturation and mode collapse, by introducing latent structure. Techniques learn motion embeddings that condition both policy and discriminator, thereby stabilizing training and supporting controllable behavior generation. These latent-conditioned GANs can also model semantic structure in motion space, facilitating interpolation and compositionality.
Despite these benefits, GAN-based methods remain prone to training instability, require careful discriminator design, and often offer coarser control over motion details. Their implicit reward structure can obscure performance tuning and requires auxiliary mechanisms for precise task alignment.
Feature-Based Methods
In contrast, feature-based imitation methods like DeepMimic start with dense, per-frame reward functions derived from specific motion features. This yields strong supervision for motion matching, making them highly effective for replicating fine-grained details in demonstrated behavior. However, traditional approaches are limited by their dependence on hard-coded alignment and lack of structured motion representation, which restricts scalability and generalization.
Recent developments address these limitations by integrating learned motion representations into the reward and policy structure. These efforts construct latent motion embeddings to structure behavior across clips, enabling smoother transitions and support for more diverse or compositional motions. This new generation of feature-based methods retains interpretability and strong reward signals while gaining some of the flexibility previously unique to GAN-based setups.
Nevertheless, feature-based systems still face challenges in adapting to auxiliary tasks or goals that require deviation from the reference trajectory. Their strong reliance on explicit tracking and dense supervision can make them brittle in dynamic or multi-objective settings, where flexibility is crucial.
| Criterion | GAN-Based Methods | Feature-Based Methods |
|---|---|---|
| Reward signal | implicit, coarse | explicit, dense |
| Scalability | high (unstructured data) | moderate (depends on representation) |
| Generalization | strong with latent conditioning | strong with good embeddings |
| Training stability | challenging (saturation, collapse) | stable but sensitive to inductive bias |
| Interpretability | low to moderate | high |
| Control | indirect (via discriminator or latent) | direct (via features or embeddings) |
| Task integration | flexible | precise but less adaptable |
On Metrics and Misconceptions
Moreover, these high-level metrics offer limited diagnostic value when comparing algorithm classes. They do not capture fundamental differences in reward design, training stability, scalability, or generalization capacity. A GAN-based approach may yield visually smoother transitions due to its distributional objectives, but this benefit must be weighed against the challenges of motion diversity and tracking accuracy. Conversely, a feature-based method may produce high-fidelity imitation in terms of kinematic features but struggle with generalization due to its reliance on well-structured representations. To conduct a rigorous and meaningful comparison between methods, evaluation should focus on the properties most directly influenced by algorithmic design. These include reward signal quality, training stability, generalization to novel motions or environments, and adaptability to auxiliary tasks. By focusing on such factors, researchers and practitioners can better understand the operational trade-offs between feature-based and GAN-based approaches, avoiding overgeneralized claims and grounding comparisons in algorithmic substance rather than incidental outcome metrics.
Debunking Common Beliefs
Despite a growing body of research, misconceptions remain prevalent in discussions of GAN-based versus feature-based learning from demonstrations. Below, we revisit some common claims, clarify their limitations, and situate them within a more rigorous analytical framework.
GAN-based methods automatically develop a distance metric between reference and policy motions.
This is partially true. GAN-based methods implicitly learn a similarity function via the discriminator. However, this function may be ill-defined in early training, leading to discriminator saturation, where the discriminator assigns uniformly high distances regardless of policy improvement. Moreover, the discriminator may conflate resemblance to a single exemplar with similarity to the overall distribution, resulting in mode collapse. Thus, while a learned metric exists, its utility and stability depend heavily on discriminator design and representation quality.
GAN-based methods do not require hand-crafted features.
No. This assertion overlooks a key implementation detail: the discriminator operates on selected features of the agent state. Choosing these features is analogous to defining reward components in feature-based methods. Insufficient features can prevent the discriminator from detecting meaningful discrepancies, while overly complex inputs can lead to rapid overfitting and saturation. This trade-off is particularly critical in tasks involving partially observed context (e.g., terrain or object interactions), where feature selection significantly impacts training stability and convergence.
GAN-based methods avoid hand-tuned reward weights for different features.
Not quite. While adversarial methods circumvent explicit manual weighting of reward components, they are still sensitive to feature scaling and normalization. Input magnitudes shape the discriminator’s sensitivity and therefore act as an implicit weighting scheme. Poorly calibrated inputs can bias the reward signal, undermining the interpretability and reliability of the learned policy.
GAN-based methods yield smoother transitions between motions.
This holds true only relative to early feature-based methods that lacked structured representations and relied on hard switching between clips. Modern feature-based methods that leverage structured motion embeddings can produce smooth, semantically meaningful transitions. Interpolation in learned latent spaces supports temporally and spatially coherent motion generation, rivaling or exceeding GAN-based transitions when appropriate representation learning is applied.
Only GAN-based methods can be combined with task rewards.
No. Both GAN-based and feature-based methods can incorporate task objectives. Feature-based methods provide dense, frame-aligned imitation rewards, making them effective when the task aligns closely with the reference motion, but less flexible when deviation is required. In contrast, GAN-based methods offer distribution-level supervision, enabling greater adaptability to auxiliary goals. This flexibility, however, comes at the cost of lower fidelity to the reference and a risk of mode collapse.
GAN-based methods deal better with unstructured or noisy reference motions.
This is an oversimplification. GAN-based methods can exhibit robustness to small inconsistencies in demonstrations due to their distributional supervision. However, this robustness often comes at the cost of discarding fine motion details. Feature-based approaches, especially those employing probabilistic or variational models, can also handle noise effectively through regularization and representation smoothing.
GAN-based methods scale better.
Not necessarily. Scalability is more a function of motion representation quality than of paradigm. Both GAN-based and feature-based methods can scale with large datasets if equipped with appropriate latent encodings. The difference lies in when and how these representations are learned—feature-based methods often rely on supervised or self-supervised embeddings, while GAN-based methods may induce representations via adversarial feedback. Neither approach guarantees scalability without careful design.
GAN-based methods transfer better to real-world deployment.
No. There is no intrinsic connection between the choice of imitation algorithm and sim-to-real transfer efficacy. Transferability is determined primarily by external strategies such as domain randomization, system identification, and regularization. While GAN-based approaches may respond more flexibly to auxiliary rewards, they are also more sensitive to regularization, which can create the false impression that certain regularizers are more effective in these methods.
Feature-based methods generalize better to unseen motion inputs.
Generalization depends less on the reward structure and more on the quality and organization of the motion representation space. Both GAN-based and feature-based methods can generalize effectively when equipped with well-structured embeddings. Failure modes arise not from the paradigm itself but from inadequate inductive biases, insufficient diversity in training data, or poor temporal modeling.
Feature-based methods are easier to implement.
Not necessarily. Designing robust feature-based systems involves selecting appropriate reward features, constructing phase functions or embeddings, and managing temporal alignment. These tasks can be as complex as designing a discriminator, particularly when the goal is to scale across tasks or environments. Moreover, effective latent representations often require pretraining and careful architectural choices to avoid collapse or disentanglement failure.
Final Remarks
This survey has examined two major paradigms in learning from demonstrations: feature-based and GAN-based methods, through the lens of reward structure, scalability, generalization, and representation. The core distinction lies not merely in architectural components but in their respective philosophies of supervision: explicit, hand-crafted rewards versus implicit, adversarially learned objectives.
Feature-based methods offer dense, interpretable rewards that strongly anchor the policy to reference trajectories, making them well-suited for tasks requiring high-fidelity reproduction of demonstrated motions. However, they often struggle with generalization, particularly in multi-clip or unstructured settings, due to the need for manually specified features and aligned references.
GAN-based methods, in contrast, provide more flexible and data-driven reward structures through discriminative objectives. This enables them to scale naturally to diverse datasets and to support smoother transitions and behavior interpolation. Yet, they often encounter challenges related to training stability, reward sparsity, and loss of fine-grained motion detail.
It is important to recognize that many problems commonly attributed to one paradigm reappear in different forms in the other. For instance, mode collapse in GANs mirrors the brittleness of poor motion representations in feature-based methods. Similarly, while feature-based methods offer strong guidance for motion tracking, they may fail to generalize or adapt when rigid reward definitions are misaligned with auxiliary tasks or dynamic environments.
Ultimately, the decision between using a feature-based or GAN-based approach is not a question of universal superiority. Instead, it should be guided by the specific constraints and priorities of the application: fidelity versus diversity, interpretability versus flexibility, or training simplicity versus large-scale generalization. Understanding these trade-offs and their relationship to reward structure and motion representation is essential for designing robust, scalable, and expressive imitation learning systems.
Citation
@article{li2025learning,
title={Learning from Demonstrations: Feature-Based and GAN-Based Approaches},
author={Li, Chenhao and Hutter, Marco and Krause, Andreas},
journal={arXiv preprint arXiv:2507.05906},
year={2025}
}