Actor-Critic Reinforcement Learning for a Lunar Lander
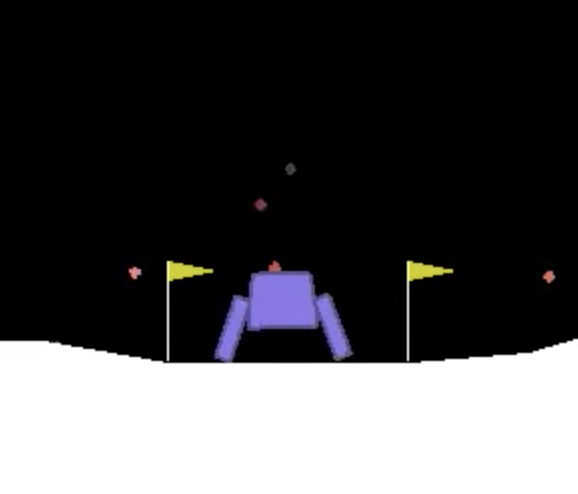 Lunar Lander Landing between Flags
Lunar Lander Landing between FlagsDescription
The objective of the project is to learn a policy to smoothly descend a lunar lander to the ground in between two flags with minimal fuel use and without collapsing. To this end, Generalized Advantage Estimation (GAE) is used to estimate actor and critic, respectively, while decreasing the variance of the policy gradient estimates and keeping them unbiased.
Chenhao Li
Reinforcement Learning for Robotics
My research interests focus on the general field of robot learning, including reinforcement learning, developmental robotics and legged intelligence.