Constrained Style Learning from Imperfect Demonstrations under Task Optimality
 ConsMimic
ConsMimicAbstract
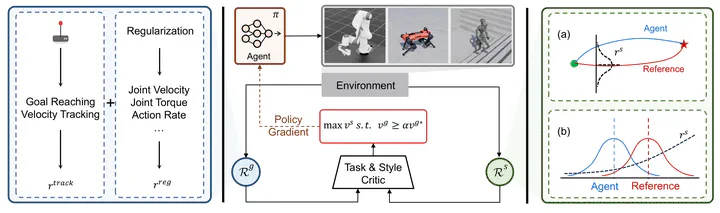
Learning from demonstration has proven effective in robotics for acquiring natural behaviors, such as stylistic motions and lifelike agility, particularly when explicitly defining style-oriented reward functions is challenging. Synthesizing stylistic motions for real-world tasks usually requires balancing task performance and imitation quality. Existing methods generally depend on expert demonstrations closely aligned with task objectives. However, practical demonstrations are often incomplete or unrealistic, causing current methods to boost style at the expense of task performance. To address this issue, we propose formulating the problem as a constrained Markov Decision Process (CMDP). Specifically, we optimize a style-imitation objective with constraints to maintain near-optimal task performance. We introduce an adaptively adjustable Lagrangian multiplier to guide the agent to imitate demonstrations selectively, capturing stylistic nuances without compromising task performance. We validate our approach across multiple robotic platforms and tasks, demonstrating both robust task performance and high-fidelity style learning. On ANYmal-D hardware we show a 14.5% drop in mechanical energy and a more agile gait pattern, showcasing real-world benefits.
Type
Publication
In Conference on Robot Learning