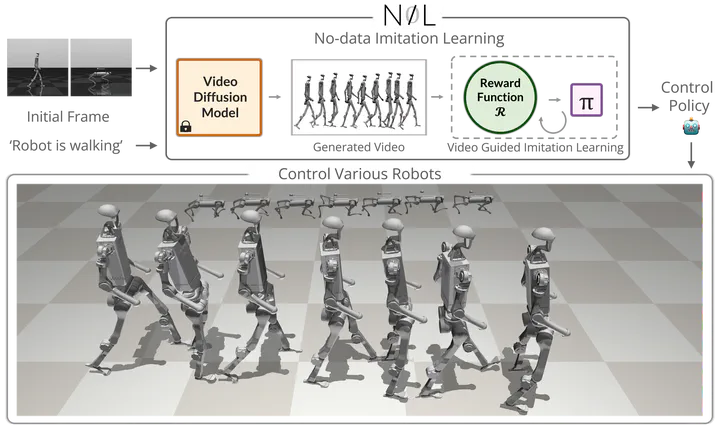
NIL: No-data Imitation Learning
Feb 1, 2026· ,,,,·
0 min read
,,,,·
0 min read
Mert Albaba
Chenhao Li
Markos Diomataris
Omid Taheri
Andreas Krause
Michael J. Black
 No-data Imitation Learning
No-data Imitation LearningAbstract
Acquiring physically plausible motor skills across diverse and unconventional embodiments, including humanoids and quadrupeds, is essential for advancing character simulation and robotics. Traditional methods, such as reinforcement learning (RL), require extensive reward function engineering. Imitation learning (IL) offers an alternative but relies heavily on curated 3D expert demonstrations, which are scarce and difficult to obtain for non-human morphologies. Video diffusion models, on the other hand, are capable of generating realistic-looking videos of various morphologies, from humans to ants. However, these videos are often not physically plausible, which limits their direct use for skill acquisition. We introduce “No-data Imitation Learning” (NIL): an imitation learning framework that replaces curated expert demonstrations with videos generated by a pretrained video diffusion model. Our key insight is that the physics simulator enforces physical constraints, while the video provides visual guidance. NIL learns 3D motor skills in a physics simulator from 2D-generated videos, with generalization capability to unconventional forms. Specifically, NIL computes a discriminator-free imitation reward that combines (i) a video-embedding similarity between generated and simulated videos using a pretrained video vision transformer, and (ii) an image-based similarity term derived from video segmentation masks. We evaluate NIL on locomotion and whole-body control tasks across unique body configurations. Our experiments show that in humanoid locomotion, NIL matches the performance of state-of-the-art IL baselines trained on motion-capture data; and in whole-body manipulation, it exceeds the performance of RL baselines without requiring any curated data.
Type
Publication
In Conference on Computer Vision and Pattern Recognition